Tutorial: Wie ich Stanford NER mit deutschen Classifiern installiere und nutze
Inhalt / Content
Ich habe ein paar Stunden, wenn nicht gar Tage, damit verbracht, den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More (Named Entity Recognizer) zum Laufen zu bringen. Dabei ist es eigentlich ganz einfach. Damit euch das nicht passieren kann, schreibe ich diese Anleitung. Sie ist speziell für Geisteswissenschaftler*inne gedacht, die gerne digitale Tools nutzen möchten, sich aber noch nicht allzu viel mit Programmierung auseinandergesetzt haben. In fünf einfachen Schritten gelangst du hier also zu einem getaggten Text – auf Englisch oder Deutsch. Wenn du Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More mit deutschen Classifiern zusammen mit einem Annotationstool wie CATMA nutzen möchtest, findest du übrigens hier eine Anleitung dazu.
Was kann Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More mit deutschen Classifiern leisten?
Named Entity RecognitionAuch als NER bezeichnet, ist eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More, kurz NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More, ist eine Technik, die bestimmte Entitäten (z.B. Orte oder Personen) in einer Reintextdatei mit Tags versehen kann. Das Verfahren beruht auf grammatischen Erkenntnissen aus der Linguistik und ist für die Kategorien Personen, Orte und Organisationen bereits recht gut entwickelt. Leider verhalten sich Sprachen unterschiedlich regelmäßig und so ist die Klassifizierung für Englisch momentan noch eine der besten. Der Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More mit deutschen Classifiern funktioniert nicht ganz so gut, kann aber trotzdem eine große Hilfe sein. An einer Verbesserung der deutschen NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More wird derzeit noch geforscht.
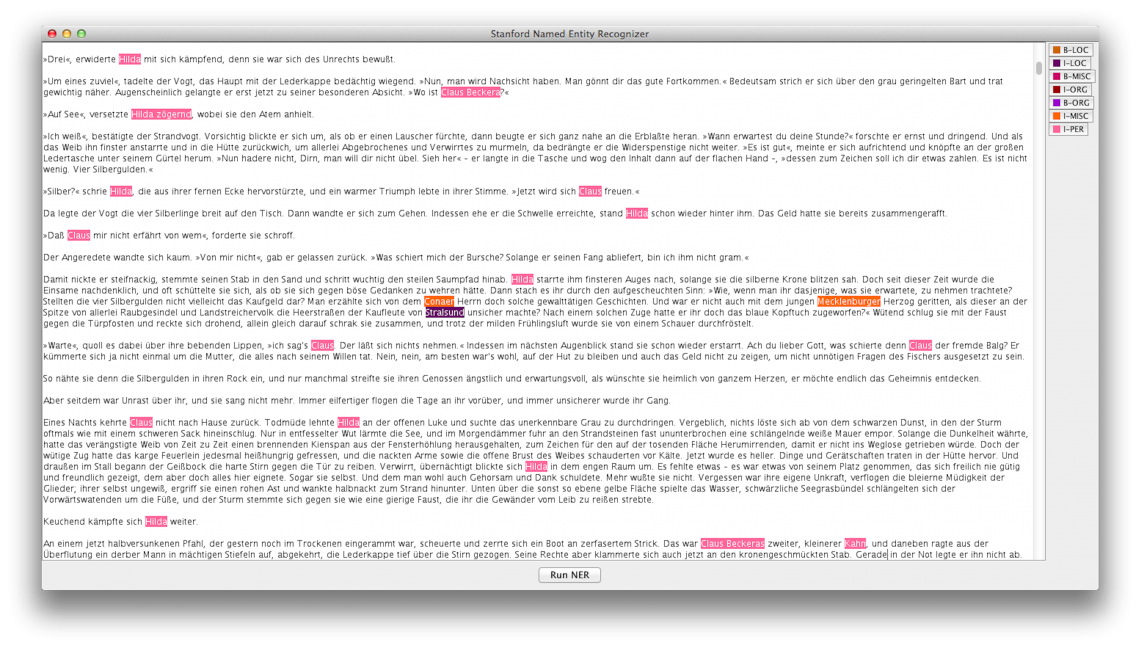
Wer sich aber mit einer ungefähren Genauigkeit von 60-70% zufrieden gibt, kann den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More mit einer deutschen Erweiterung nutzen. Diese versieht Personen, Orte, Organisationen und Verschiedenes mit Tags, das heißt, dass am Ende entweder ein Text im grafischen User Interface steht, der mit farbigen Markierungen versehen ist oder man einen Reintext speichern kann, der alle Entitäten etwa so aussehen lässt (Beispiel Ort Hamburg): < I-LOC > Hamburg < / I-LOC > Für die qualitative Textanalyse bedeutet das zunächst einmal (nur), dass man den Text für weitere Programme aufbereitet, die dann z.B. Häufigkeiten auswerten – aber zu solch einer Weiterverwendung komme ich ein andern Mal in einem anderen Artikel.
1. Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More installieren
Das Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More Package bekommst du als zip-Datei hier. Voraussetzung dafür, dass du den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More zum Laufen bringst, ist, dass du eine aktuelle Version von Java installiert hast. Lade das Archiv herunter und öffne es. Auf einem Mac-PC wird es in der Regel automatisch entpackt, auf einem Windows Rechner musst du diesen Schritt meist extra ausführen. Die letzte Hürde über die du springen musst, um zum grafischen Interface des NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More zu gelangen, ist, das richtige Icon auszuwählen. Auf dem Mac-PC heißt dies Stanford-ner.jar und sieht etwa so aus:
Auf einem Windows-Rechner heißt die Datei, die zur Ausführung des NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More führt NER-GUI und ist eine batch Datei. Im Ordner sieht das Ganze so aus =>
Oder in anderem Betriebssystem auch mal so:
2. Classifier laden
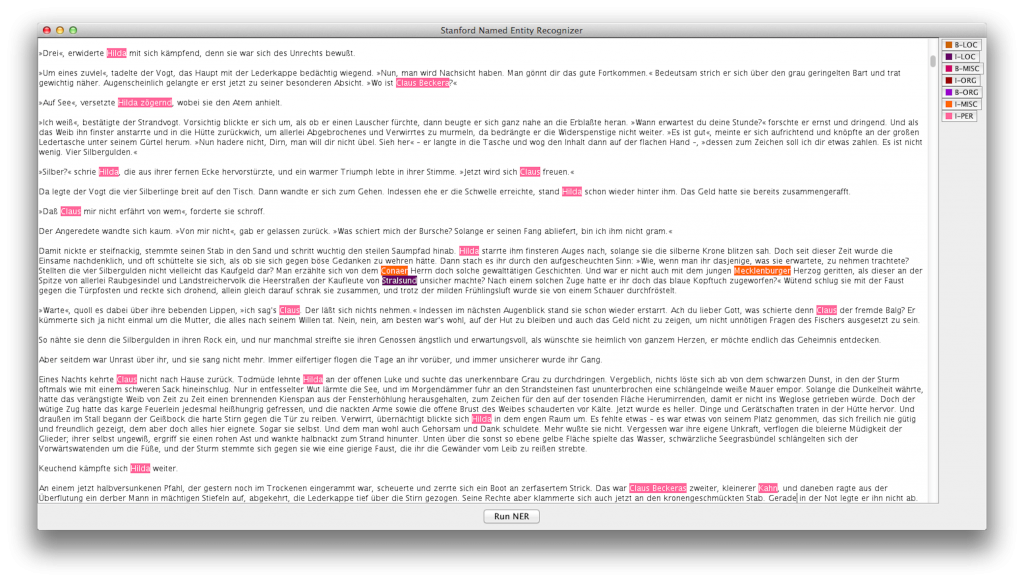
Mit dem Doppelklick auf das entsprechende Icon öffnet sich ein GUI, das quasi die Rohversion des Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More zeigt und damit noch nicht verwendbar ist. Es fehlen die Kategorien, die getaggt werden sollen. Das Stanford Packet bringt 3 Klassifizierungssysteme mit, die allesamt für die englische Sprache ausgelegt sind. Sie verfügen über 3, 5 oder 7 verschiedene Entitäten-Tags. Du lädst diese, indem du auf Classifier gehst, dort „load CRF from file“ anwählst und dann den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More Ordner anwählst. Wie du auf der Grafik oben siehst, gibt es dort einen Ordner mit „Classifier“. Diesen wählst du aus und gehst dann auf die entsprechende gz-Datei für 3, 5 oder 7 Entitäten. Es dauert einen Moment, bis rechts am GUI eine Leiste erscheint, die Farben und Beschreibungen der Tags anzeigt.
3. Text laden
Nun kannst du einen Text per Copy/Paste einfügen oder eine ganze Datei laden. Diese sollte ein Reintextformat haben, wie etwa txt und zumeist funktioniert die übliche UTF-8 Codierung. Du lädst die Datei wie in einem Textverarbeitungsprogramm über File>Open File und dann wählst du von deiner Festplatte. Wieder dauert es einen Moment bis der Text im GUI erscheint.
4. Run NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More
Nun ist dein getaggter Text tatsächlich nur noch einen Mouseklick entfernt. Du gehst auf „Run NER“ ganz unten in der Mitte. Kurze Texte werden nun sehr schnell mit den farbigen Markierungen angezeigt. Längere Texte können schon einmal einen Moment brauchen. Ich habe den ersten Test mit einem 500 Seiten starken Roman gemacht und es dauerte etwa 4 Minuten bis das Programm diesen gelesen hatte. Unter File>save tagged file kannst du dein Ergebnis nun speichern. Siehst du es dir z.B. im Wordpad an, wirst du sehen, dass wie oben beschrieben nun die Tag-Befehle eingefügt sind.
5. Deutsche Klassifikation hinzufügen
Um den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More mit deutschen Classifiern nutzen zu können, brauchst du eine deutsche Erweiterung für den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More, die du hier herunterladen kannst. Wieder handelt es sich um eine Archivdatei. Da diese nicht im zip sondern in einem tar-Format gespeichert ist, kann es sein, dass du ein extra Programm zum Entpacken brauchst (zumindest auf einem Windows-PC, Macs entpacken es in der Regel automatisch). Schiebe den entpackten Ordner in den Classifier-Ordner des Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More. Öffne jetzt das Programm und wähle Classifier>Load CRF from file>StanfordNER>Classifier>Stanford-ner-2012-05-22-german und wähle dann eine der beiden gz-Dateien aus.
Nach einer Weile erscheinen 7 Tagfarben und Beschreibungen an der rechten Seite. Die deutsche Erweiterung verfügt über vier Kategorien – Personen, Orte, Organisationen und Vermischtes, drei davon in den Ausprägungen I und B. Jetzt kannst du den Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More mit deutschen Classifiern nutzen, indem du wie oben beschrieben bei Schritt 3 weiter gehst. So kommst du endlich zu einem getaggten Text auf Deutsch. Wie es dann damit weitergehen kann – das herauszufinden wird meine nächste Aufgabe sein. Ich werde dir an gleicher Stelle davon berichten.
English Version:
I spend a few hours – maybe even days – to find out how to run the Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More (Named Entity Recognizer) on my computer, although it is actually very easy. As I think this is due to a dramatic lack of simple NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More tutorials, I decided to write one for this blogBlog ist kurz für Web-Log und steht für ein online Publikationsformat. Man kann sowohl der als auch das Blog sagen. Es gibt Blogs aller Sparten, von Linklisten über Tagebuchartige Formate bis hin zu wissenschaftlichen Blogs. Die Veröffentlichung kann schnell und unkompliziert erfolgen oder redaktionellen Standards entsprechen. In den Geisteswissenschaften etablieren sich Blogs zunehmend als Alternative zur langwierigeren wissenschaftlichen Publikation. Lebe lieber literarisch ist ein populärwissenschaftlicher Literaturblog. Kurze Podcast-Folge zum Blog-Begriff: https://hnp9zs.podcaster.de/download/Podcast_Blog(1).mp3 More. So this is to all the humanists who did not yet take the chance to have a closer look at programming issues and, nevertheless, want to use the Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More – be it in English or in German (or others).
What does NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More do?
NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More is a technique to tag named entities (as places or names) in a raw text file. The program uses grammatical constructions to recognize named entities. NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More works quite well on the English language but as some languages are not as regular as English there are differences in the output quality. I know that in the German speaking countries many Digital Humanist work on improving NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More for German at the moment. But if you want to try it right now with the existing Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More package for German, I will explain how to make it work in five steps in this article.

1. Install Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More
You get the Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More package as a zip-file here (you will need the newest java version for running the program). If you have a mac the file will probably unpack automatically. If you are working with windows, you will have to do that yourself after downloading. Last thing you have to do is open the folder and choose the right icon. On a mac it will be called stanford-ner.jar and look like this:
For windows the program is called NER-GUI and comes as a batch file. In your Folder, it will probably look like this:

2. load Classifier
By doubbleclicking you will proceed directly to the GUI (Graphic User Interface) which is, so to say, a raw version of the NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More. You still need to add the categories for tagging your text. Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More comes with three packages of classifiers – one with three, one with five and one with seven categories. You can load them by going to classifier>load CRF from file. You may then choose one of the gz-files from the classifier folder inside the Stanford-NER package. It will take a moment until the classifiers show up on the right side of your GUI.
3. load text
You may now either copy/past a text into the NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More or load a file from your hard drive. In order to do so make sure that you have a raw text file such as txt; generally a UTF-8 coding will do, but in some languages you might have to change that. Go to File>Open File and choose your text. Again, it may take a little time to open the text if it is a huge file.
4. Run NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More
From now on your tagged text is literally only a mouse click away. Go to „run NER“ at the bottom of you GUI. If your text is short the tagged version will appear in no time, but when I tested the NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More first with a novel of about 500 pages, it took the NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More a couple of minutes to tag it. You can save your tagged file via File>save tagged file. If you open it in a plain text editor such as word pad, you will see the tags in the form of < tag name > Entity < / tag name >.
5. Load German (or other language)
You will get packages for languages other than English on the same downloading page as the Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More itself. Again you must download the archived files to your computer and unpack them. In the case of the German package the archive comes in a tar file which probably needs an other program to unpack as a zip file (at least if you’re working with windows, for mac unpacking will do automatically). Move the new language classifiers folder into the Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More classifiers folder. Now open the NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More GUI and go to Classifier>Load CRF from file>StanfordNER>Classifiers>Stanford-ner-2012-05-22-german (or other language) and chose one of the two (this is again for the example of the German classifiers) gz-files.
Your tags will appear on the right side of the GUI and you can proceed as explained in Step 3-5. How you could go on doing literary text analysis once you have your text tagged by the Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More is another question, which I will further investigate from now on. Of course I will share my experiences with you once I am done with that.




9 Kommentare
Pingback:
Pingback:
Pingback:
Tim
Vielen Dank für deine Erklärung, Mareike! Ich versuche schon seit einer Weile erfolglos den classifier von Sebastion Padó zum laufen zu bringen, aber irgendwie mag meine Java version das Format nicht. Der, den du hier verlinkst, funktioniert wunderbar. Für solche Momente liebe ich das Internet. Beste Grüße!
Sarah
Hallo,
erstmal ein Riesendankeschön, das hat mir gerade unglaublich das Leben erleichtert. Ich hatte genau das gleiche Problem wie Tim. Allerdings habe ich mich auch gefragt, was die B- und I- Ausprägungen bedeuten sollen („…Die deutsche Erweiterung verfügt über vier Kategorien – Personen, Orte, Organisationen und Vermischtes, drei davon in den Ausprägungen I und B.“…), und hab grade etwas dazu gefunden. Vielleicht ist es ja auch hier von Interesse. 🙂
„…to indicate the >BIO<utside of a named entity. You will see that each major BIO tag is followed by the corresponding named entity category. For instance, the tag B-PER indicates the beginning of a person name, I-PER indicates inside a person name, and so forth."…) http://www.isi.edu/natural-language/teaching/cs544/spring13/lectures/kozareva-assignment-1-2013.pdf, (16.01.17)
Nochmals dankeschön!
Beste Grüße!
Sarah
Hm, das ist nicht so ganz angekommen wie es sollte. Die erste Zeile im zweiten Absatzu sollte eigentlich folgendermaßen lauten:
„…to indicate the ‚B’eginning of a named entity, the ‚I’nside of a named entity and the ‚O’utside of a named entity…“
Tut mir leid ^_^
MareikeSchumacher
Liebe Sarah, super, vielen Dank dafür 🙂 Liebe Grüße, Mareike
Pingback:
Pingback: