Tutorial: Wie ich CATMA und Stanford NER zusammen nutze
Inhalt / Content
Ich gebe zu, dass wahrscheinlich 10% meiner Liebe zu dem Tool CATMA (Computer Aided Textual Markup and Analysis) nur daher stammt, dass es von meinen Kollegen in Hamburg entwickelt wird, die niemals müde zu werden scheinen, wenn Nutzer wie ich immer neue Funktionalitäten haben wollen. Aber so bleiben immer noch 90%, die daher rühren, dass dieses Programm inzwischen eine große Vielfalt an Nutzungsmöglichkeiten bietet, sodass ich immer wieder dazu zurückkehre. Selbst, wenn ich mir mal vornehme, einen anderen Weg zu gehen, kehre ich doch immer wieder um. So geschah es also auch als ich nach Weiterverwendungsmöglichkeiten für meine NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More (Named Entity RecognitionAuch als NER bezeichnet, ist eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More – mehr darüber hier) Ergebnisse suchte. Als jetzt im neuen CATMA-Release auch noch eine Funktion zur xml Erkennung freigeschaltet wurde, wurde das Ganze sogar noch einmal einfacher. Darum zeige ich dir heute, wie man CATMA und Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More zusammen nutzen kann.
Import in CATMA und Stanford NER-getaggte Texten
Zur Named Entity RecognitionAuch als NER bezeichnet, ist eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More verwende ich das Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More Tool; eine Anleitung zur Installation findest du hier. CATMA ist ein webbasiertes Tool, dass du nicht lokal installieren musst. Folge einfach dieser Webadresse und logge dich mit einem Google bzw. Open ID Account ein und du kannst loslegen.
Stanford NER Texte zum Import vorbereiten
Hast du einen Text mit dem Stanford NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More Tool getaggt, so speichere ihn als getaggte Datei mit einem leicht wiederzufindenden Namen ab. Leider erhälst du damit zuerst einmal nur eine Textdatei mit einigen xml tags. Diese musst du in eine richtige xml Datei umwandeln, indem du dem Text einen entsprechenden Rahmen gibst. Dazu musst du nur einen < head > Tag vor Beginn des Textes einfügen und diesen am Ende wieder schließen. Zum Beispiel könntest du in die erste Zeile einfügen < NER-Markup > und in die letzte < / NER-Markup > (ohne Leerzeichen). Dann speichere die Datei so ab, dass sie eine .xml erweiterung hat. Das geht zum Beispiel mit den Programmen Wordpad oder TextWrangler, indem man einfach das txt zu einem xml machst.
Import in CATMA
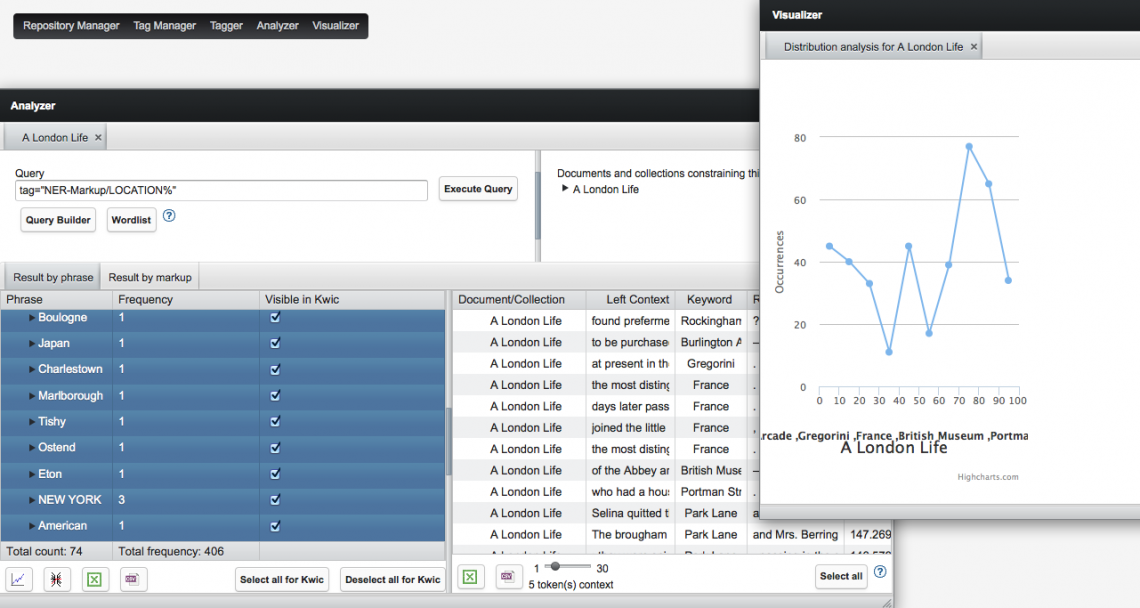
Jetzt kannst du zurück zu CATMA gehen und diese xml Datei im Schritt für Schritt Upload hochladen. CATMA wird jetzt automatisch die Datei als xml erkennen, wenn alles korrekt ausgeführt wurde. Leider wird es Probleme geben, wenn die Anführungszeichen wie folgt verwendet wurden: >…< (das kommt leider in literarischen Texten häufig vor. Da xml diese Zeichen nicht als Text, sondern als Befehle erkennt, musst du sie suchen und mit „…“ ersetzen. Auch dieses Zeichen & bereitet leider Probleme und sollte durch „und“ ersetzt werden. Wenn der Upload erfolgreich war, wirst du nun eine Datei haben, die in einem „Intrinsic Markup Collection“ genannten Bereich all deine NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More Tags gespeichert hat und bei Abruf als farbige Markierungen im Text anzeigt:
Analysiere deine NER-Ergebnisse direkt in CATMA
Als nächstes kannst du zu „analyse document“ gehen, um deine Daten weiter zu verarbeiten. Es wird sich ein neues Fenster öffnen, in dem du in einer Commandline reguläre Ausdrücke eingeben kannst, um deinen Text zu durchsuchen. Alternativ kannst du auch dem grafischen Klick-System folgen, dass dich über den Button „build query“ durch ein Such-System leiten wird, mit dem du Tags, Worte oder Kollokationen suchen kannst.
Wenn du in die Commandline z.B. tag=“NER-Markup/LOCATION%“ eingibst, so wirst du eine Liste aller Ortsnamen im Text bekommen. Wähle alle angezeigten Ergebnisse aus und du bekommst auf der rechten Seite des Fensters eine Keyword in Context Anzeige, die dir die Ortsnamen mit jeweils 5 Wörtern davor und danach anzeigt. Unterhalb dieses Fensters findest du kleine Symbole, die dir den Export als xls oder csv Tabellendokument erlauben. Die heruntergeladene Datei kannst du in Excel ansehen und weiter bearbeiten. Oder du kannst die Tabelle weiterhin über CATMA anschauen und dir die einzelnen Ortsnamen im Text anzeigen lassen, indem du doppelt darauf klickst. Außerdem kannst du dir Visualisierungen deiner Daten erstellen lassen, indem du auf die Symbole für „distribution graph“ oder „treemap“ klickst.
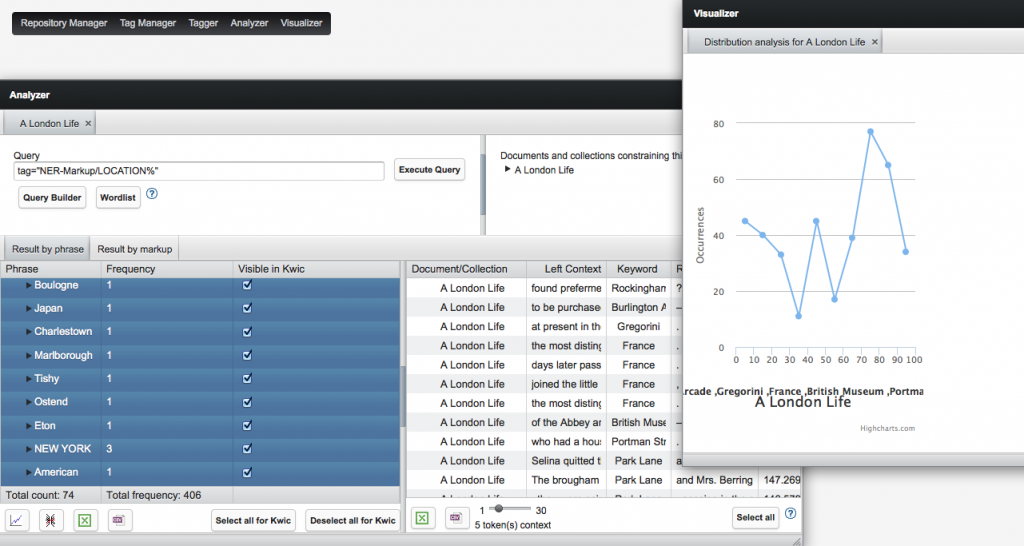
Natürlich kannst du auch – so wie ich es getan habe – deine Rohdaten im Tabellendokument für die Weiterverarbeitung aufbereiten. Hier kannst du z.B. alle vom NERSteht für Named Entity Recognition, eine Methode bei der eindeutig benannte Größen (Entitäten) automatisch vom Computer erkannt und im Text markiert werden. Typische Beispiele für NER-Kategorien sind Personen, Orte und Organisationen. More Tool falsch erkannten Entitäten löschen (in der deutschen Version werden das recht viele sein, im Englischen hingegen eher Ausnahmefälle). Schließlich kannst du diese Daten nutzen, um sie z.B. in ein Geolokalisationstool zu übertragen. Wie du das machen kannst, werde ich demnächst auf diesem BlogBlog ist kurz für Web-Log und steht für ein online Publikationsformat. Man kann sowohl der als auch das Blog sagen. Es gibt Blogs aller Sparten, von Linklisten über Tagebuchartige Formate bis hin zu wissenschaftlichen Blogs. Die Veröffentlichung kann schnell und unkompliziert erfolgen oder redaktionellen Standards entsprechen. In den Geisteswissenschaften etablieren sich Blogs zunehmend als Alternative zur langwierigeren wissenschaftlichen Publikation. Lebe lieber literarisch ist ein populärwissenschaftlicher Literaturblog. Kurze Podcast-Folge zum Blog-Begriff: https://hnp9zs.podcaster.de/download/Podcast_Blog(1).mp3 More erklären.


Die besten Bücher 2014
Das könnte dich auch interessieren

Kritische Digital Humanities, gibt es das nicht schon längst?
Transgender – eine geisteswissenschaftliche Perspektive
